Relational databases are most powerful when designed with clarity, scalability, and normalization in mind. In this article, we’ll explore a structured PostgreSQL data model for managing sports tournaments. We’ll break down each table, the relationships between them, and how this design supports efficient queries and data integrity.
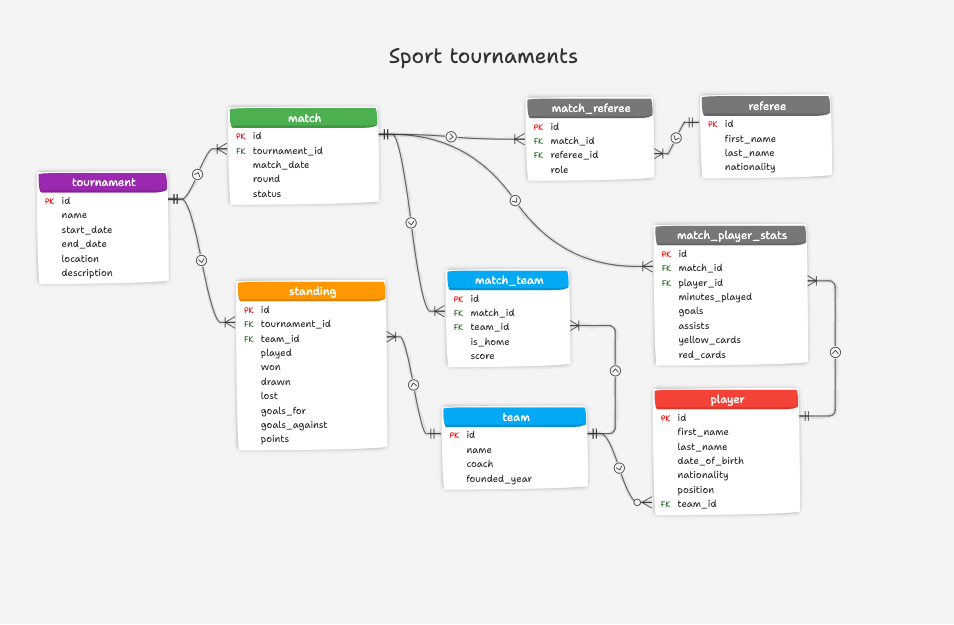
Overview: What Does This Schema Store?
This schema models the core data entities and relationships involved in managing team-based sports tournaments, such as football or basketball. It includes:
- Tournaments
- Matches
- Teams and Players
- Match statistics
- Referees and
- Tournament standings
Table Breakdown
1. Table tournament: Defining the Competition

CREATE TABLE public.tournament(
id serial NOT NULL,
"name" character varying(150) NOT NULL,
start_date date NOT NULL,
end_date date,
"location" json,
description text,
CONSTRAINT tournament_pkey PRIMARY KEY(id)
);Purpose: Stores tournament metadata.
Key Features:
locationas JSON allows flexibility (e.g., city, coordinates).descriptionallows free-form notes or extra context.
Why it works: Keeps the schema flexible and open-ended without forcing extra joins for optional or non-relational data.
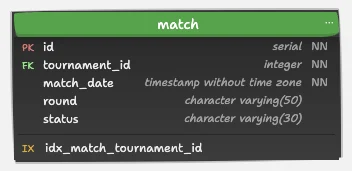
2. Table match: The Centerpiece of the Game Schedule
CREATE TABLE public."match"(
id serial NOT NULL,
tournament_id integer NOT NULL,
match_date timestamp without time zone NOT NULL,
round character varying(50),
status character varying(30),
CONSTRAINT match_pkey PRIMARY KEY(id)
);
CREATE INDEX idx_match_tournament_id ON public."match"
USING btree (tournament_id NULLS LAST);Purpose: Stores each match’s metadata.
Relationship: Matches belong to tournaments via tournament_id.
Design Notes:
statuscan reflect states like ‘Scheduled’, ‘Completed’ etc.- Indexed on
tournament_idfor quick filtering.
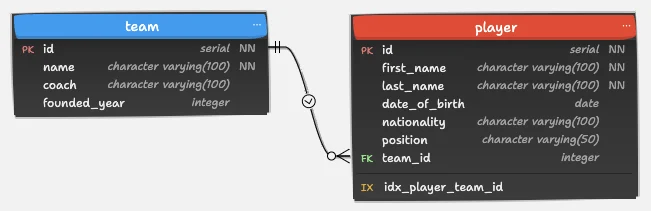
3. Tables team and player: The Squad and Its Members
CREATE TABLE public.team(
id serial NOT NULL,
"name" character varying(100) NOT NULL,
coach character varying(100),
founded_year integer,
CONSTRAINT team_pkey PRIMARY KEY(id)
);
CREATE TABLE public.player(
id serial NOT NULL,
first_name character varying(100) NOT NULL,
last_name character varying(100) NOT NULL,
date_of_birth date,
nationality character varying(100),
"position" character varying(50),
team_id integer,
CONSTRAINT player_pkey PRIMARY KEY(id)
);
CREATE INDEX idx_player_team_id ON public.player USING btree(team_id NULLS LAST);
ALTER TABLE public.player
ADD CONSTRAINT player_team_id_fkey
FOREIGN KEY (team_id) REFERENCES public.team (id) ON DELETE Set null
ON UPDATE No action
;Normalization Strategy:
- Players link to teams via
team_id. - When a team is deleted,
team_idbecomes NULL rather than cascading (important to preserve player records).
Design notes:
- Indexes on
team_idensure quick joins and filters.
4. Table match_team: Linking Matches and Teams

CREATE TABLE public.match_team(
id serial NOT NULL,
match_id integer NOT NULL,
team_id integer NOT NULL,
is_home boolean DEFAULT false,
score integer,
CONSTRAINT match_team_pkey PRIMARY KEY(id),
CONSTRAINT match_team_match_id_team_id_key UNIQUE(match_id, team_id)
);
CREATE INDEX idx_match_team_match_id ON public.match_team USING btree
(match_id NULLS LAST);
CREATE INDEX idx_match_team_team_id ON public.match_team USING btree
(team_id NULLS LAST);
ALTER TABLE public.match_team
ADD CONSTRAINT match_team_match_id_fkey
FOREIGN KEY (match_id) REFERENCES public."match" (id) ON DELETE Cascade
ON UPDATE No action;
ALTER TABLE public.match_team
ADD CONSTRAINT match_team_team_id_fkey
FOREIGN KEY (team_id) REFERENCES public.team (id) ON DELETE Cascade
ON UPDATE No action;Purpose: Represents team participation in a match.
Design Features:
is_homeidentifies home/away team.scoresimplifies result tracking.
Why separate table?
- Many-to-many relationship between
matchandteam. - Additional match-specific attributes per team.
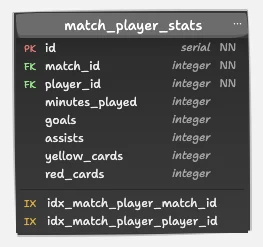
5. Table match_player_stats: Player Performance per Match
CREATE TABLE public.match_player_stats(
id serial NOT NULL,
match_id integer NOT NULL,
player_id integer NOT NULL,
minutes_played integer,
goals integer DEFAULT 0,
assists integer DEFAULT 0,
yellow_cards integer DEFAULT 0,
red_cards integer DEFAULT 0,
CONSTRAINT match_player_stats_pkey PRIMARY KEY(id),
CONSTRAINT match_player_stats_match_id_player_id_key UNIQUE(match_id, player_id)
);
CREATE INDEX idx_match_player_match_id ON public.match_player_stats USING btree (match_id NULLS LAST);
CREATE INDEX idx_match_player_player_id ON public.match_player_stats USING btree (player_id NULLS LAST);Purpose: Tracks player level stats in a specific match.
Normalization at work: No redundant data like player name or team name – only keys and metrics.
Unique Constraint ensures no duplicate stat entries per player per match.
6. Tables referee and referee: Officials and Their Roles
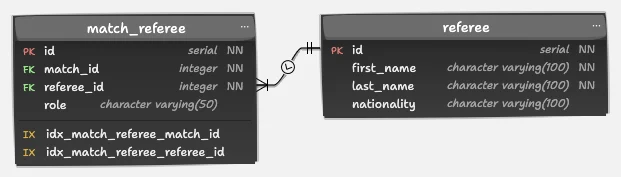
CREATE TABLE public.referee(
id serial NOT NULL,
first_name character varying(100) NOT NULL,
last_name character varying(100) NOT NULL,
nationality character varying(100),
CONSTRAINT referee_pkey PRIMARY KEY(id)
);
CREATE TABLE public.match_referee(
id serial NOT NULL,
match_id integer NOT NULL,
referee_id integer NOT NULL,
"role" character varying(50),
CONSTRAINT match_referee_pkey PRIMARY KEY(id),
CONSTRAINT match_referee_match_id_referee_id_key UNIQUE(match_id, referee_id)
);
CREATE INDEX idx_match_referee_match_id ON public.match_referee USING btree
(match_id NULLS LAST);
CREATE INDEX idx_match_referee_referee_id ON public.match_referee USING btree
(referee_id NULLS LAST);
ALTER TABLE public.match_referee
ADD CONSTRAINT match_referee_referee_id_fkey
FOREIGN KEY (referee_id) REFERENCES public.referee (id) ON DELETE Cascade
ON UPDATE No action;Design notes:
- Referees can officiate multiple matches.
- Matches can have multiple referees in different roles (e.g., main referee, assistant).
7. Table standing: Tournament Leaderboards
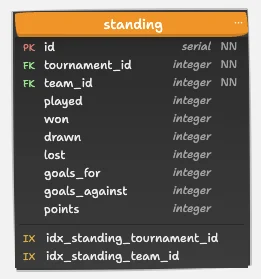
CREATE TABLE public.standing(
id serial NOT NULL,
tournament_id integer NOT NULL,
team_id integer NOT NULL,
played integer DEFAULT 0,
won integer DEFAULT 0,
drawn integer DEFAULT 0,
lost integer DEFAULT 0,
goals_for integer DEFAULT 0,
goals_against integer DEFAULT 0,
points integer DEFAULT 0,
CONSTRAINT standing_pkey PRIMARY KEY(id),
CONSTRAINT standing_tournament_id_team_id_key UNIQUE(tournament_id, team_id)
);
CREATE INDEX idx_standing_tournament_id ON public.standing USING btree
(tournament_id NULLS LAST);
CREATE INDEX idx_standing_team_id ON public.standing USING btree
(team_id NULLS LAST);Purpose: Tracks team performance per tournament.
Why it matters:
- Denormalization here is acceptable – it avoids recalculating stats from raw matches each time. Read What is database normalization for details.
- Indexed on
tournament_idandteam_idfor leaderboard generation.
Extensibility Ideas
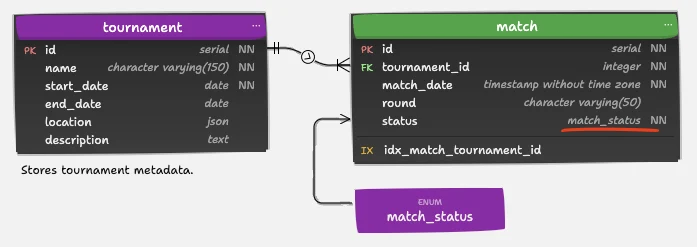
This data model provides a clean foundation that could be extended with:
- enums for easier specification of valid values (see the screenshot above)
- tables for storing data related to
injuries,substitutions,player_contracts - user-generated content like comments or ratings etc.
Visualizing and Designing the Schema with Luna Modeler
This article contains screenshots showing the database diagram and its parts. These diagrams were created in Luna Modeler – a powerful and user-friendly data modeling tool.
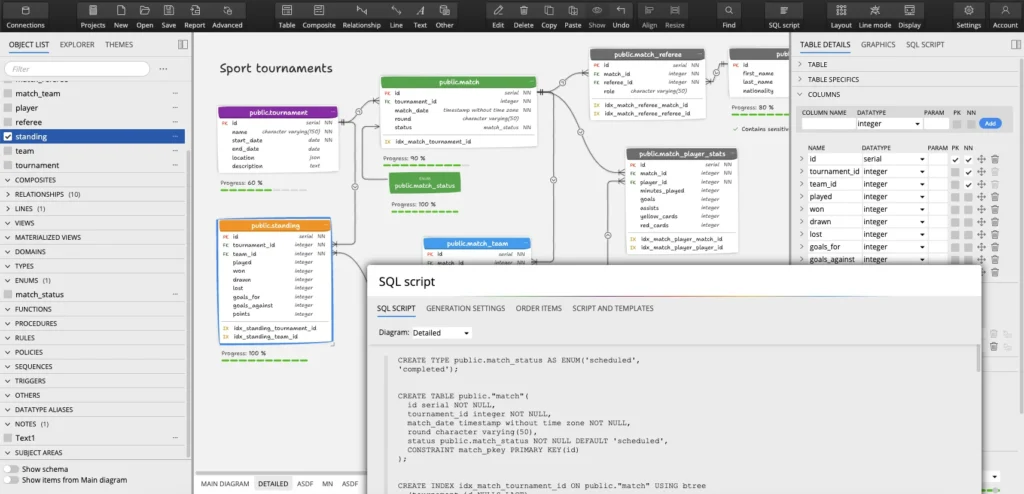
With Luna Modeler you can:
- Design database structures visually and generate SQL scripts for PostgreSQL (and other databases).
- Reverse-engineer existing databases into clear, editable diagrams.
- Easily modify and reorganize your data model using an intuitive drag-and-drop interface.
- Keep schema documentation up to date with automatically generated diagrams and reports.
- Include additional logical information – notes, priority, progress in the database design etc.
If you’d like to explore this sports tournament data model or design your own in a visual modeling environment, you can download a free trial of Luna Modeler and start building or exploring database structures today.
It’s the perfect way to both generate SQL scripts and visualize complex schemas at a glance.
FAQ
A data model is like a picture of your data and how it’s connected. It’s like a roadmap for how data is stored, organized, and manipulated within a database system.
Luna Modeler provides a user-friendly visual interface that helps users create data models, manage ER diagrams, generate SQL scripts, and document schemas with minimal effort.
Luna Modeler supports PostgreSQL, Supabase, Oracle Database, SQL Server, MariaDB, MySQL and SQLite.
Luna Modeler is designed for relational databases.
For NoSQL databases like MongoDB, try Moon Modeler.
